
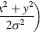













I was just looking for a good explanation of this online to point a lab member towards, and I couldn’t find anything suitable, so I thought I’d write something myself. (Since then, this https://en.wikipedia.org/wiki/Fraction_of_variance_unexplained seems pretty good.
The idea is you have a set of experimental data {Yi} (i=1 to N). These might be responses collected in N different conditions, for example.
The mean is
M = sum{Yi} / N
and the variance about this mean is the total variance
TV = var(Yi) = sum{ (Yi-M)^2 } / N
Now suppose you have some model or fit which predicts values Fi. The residuals between the fit and the data are Ri=(Yi-Fi). The mean of the squared residuals is
RV = sum { (Yi - Fi )^2 } / N
(this is identical to the variance of the residuals if Fi and Yi have the same mean, as they do in linear regression)
The fraction of UNexplained variance is RV/TV, so the fraction of explained variance is 1-RV/TV.
In a perfect world, Fi would be equal to Yi for all i, and therefore these residuals would all be zero. RV=0 and thus all of the variance is explained. The other end of the spectrum is where all the fit values are the same, just equal to the mean of the data: Fi=M. Then we can see from the equations above that RV=TV and none of the variance is explained.
The percentage of variance which is explained is
PV = 100(1-RV/TV).